Exploring the Work of HP Lovecraft with NLP
Sep 1, 2019 00:00 · 5042 words · 24 minute read
H.P. Lovecraft wrote weird fiction. The progenitor of the cosmic horror genre, his stories involve mysterious creatures so powerful and alien to us that they can’t be comprehended. Between 1917 and 1935, he wrote 64 works of fiction (plus more in collaboration with other authors). The works of Lovecraft have been adapted throughout media, from board games to stuffed animals. He mostly wrote short stories, with only a single novel and five novellas to accompany them.
His most famous works are the Cthulhu Mythos, a nebulous world of strange creatures beyond understanding. Having to contemplate these beings from beyond time and space usually drives a character mad, if they survive at all. What makes the stories more interesting is that the creatures are usually indifferent to humans, if they notice them at all. This doesn’t stop the formation of cults to the mythos creatures and leaves plenty of opportunity to find them in exotic locales. Less famous are his Dream Cycle stories. These stories take place in the dreamlands, an alternate dimension which can only be visited in peoples dreams.
He was also a huge racist and all-around terrible human being, even by the standards of his time1. But the stories are great, if you can put aside some of the not-great comments he makes from time to time. I understand that not everyone can do that.
Importantly for us, he died long enough ago that all his writings are public domain. We can do what we want with them without the copyright police coming for us. I won’t be including any explicit spoilers but I will be talking about common themes and plot elements, occasionally.
Natural Language Processing
Working through human language statistically or computationally is called natural language processing. There are a lot of libraries and functions to do this kind of analysis quicker than I will. But just importing libraries can mask what’s actually going on, which is pretty straightforward stuff. So we’ll do it out by hand, for the purposes of this post.
I’ll be using a set of 67 works collected by github user vilmibm in the repo lovecraftcorpus. Let’s all appreciate that he’s done this for us, because I absolutely didn’t feel like doing that.
Goals
I want to figure out what I should read next. The big free Lovecraft anthology I have on my kindle has a lot of stuff, and I want to prioritize. I’d like more stories like The Call of Cthulhu or The Dunwich Horror: stories about weird, incomprehensible monsters that drive you insane when you think about them. The kind of stuff you think about when you think about Lovecraft. The good stuff.
This is all going to be exploratory, unsupervised analyses. But in any analysis, its helpful to set up a couple sanity check items that we should expect (or even just like) to see. Otherwise, you’re just looking at a graph and shrugging. Mine are:
- I’d expect to see the stories from the dream cycle to be pretty identifiable. They’re so different that it should be obvious. This is a real sanity-check goal: If we can’t do this, something’s not going right.
- I’d think that The Dunwich Horror, The Call of Cthulhu, At the Mountains of Madness and The Shadow Over Innsmouth to be kind of close because they seem to reference a shared pantheon.
- I’d like to see The Call of Cthulhu assort itself with Dagon. A lot of the themes and plot elements in Dagon we reused in The Call of Cthulhu.
- I’d be interested to see if The Color Out Of Space and The Whisperer In Darkness are similar in an objective analysis.
Processwise, I’ll keep things pretty simple for this post. We’ll go over representing documents mathematically, tf-idf, cosine similarity, and touch a little bit on latent semantic analysis.
Analysis
library(tools)
library(tidyverse)
library(tokenizers)
library(stopwords)
library(ggrepel) # Makes geom_text look nicer
library(lsa)
library(reshape2)Processing
Statistics and machine learning are expressed mathematically, so we need to get these text files in to a format we can do math on. That’s why pre-processing text is so important. If you don’t get things right early, you’re going to be in trouble later. NLP is “Garbage in, garbage out”, just like anything else.
Reading the corpus
Our corpus is the collection of documents we’ll be working on. I pulled these from github, and they’re all txt files in a subfolder, all in the same format. Let’s read them in.
# Get the list of files (.txt extensions only.)
raw.corpus.fns <- list.files(".", pattern="\\.txt$", full.names=TRUE)
# This function processes each file.
# We skip the first line (the title), and skip empty lines (we don't need them),
# then concatenate the rest of the lines into one string.
read_fn <- function(fn) {
read_lines(fn, skip=1, skip_empty_rows = 1) %>%
paste(collapse=" ")
}
# Read the files
corpus <- purrr::map(raw.corpus.fns, read_fn)
process_filename <- function(s) { file_path_sans_ext(s) %>% basename() }
corpus <- set_names(corpus, nm=map_chr(raw.corpus.fns, process_filename))
names(corpus)## [1] "alchemist" "arthur_jermyn" "azathoth"
## [4] "beast" "beyond_wall_of_sleep" "book"
## [7] "celephais" "charles_dexter_ward" "clergyman"
## [10] "colour_out_of_space" "cool_air" "crawling_chaos"
## [13] "cthulhu" "dagon" "descendent"
## [16] "doorstep" "dreams_in_the_witch" "dunwich"
## [19] "erich_zann" "ex_oblivione" "festival"
## [22] "from_beyond" "gates_of_silver_key" "haunter"
## [25] "he" "high_house_mist" "hound"
## [28] "hypnos" "innsmouth" "iranon"
## [31] "juan_romero" "kadath" "lurking_fear"
## [34] "martins_beach" "medusas_coil" "memory"
## [37] "moon_bog" "mountains_of_madness" "nameless"
## [40] "nyarlathotep" "old_folk" "other_gods"
## [43] "outsider" "pharoahs" "pickman"
## [46] "picture_house" "poetry_of_gods" "polaris"
## [49] "randolph_carter" "rats_walls" "reanimator"
## [52] "redhook" "sarnath" "shadow_out_of_time"
## [55] "shunned_house" "silver_key" "street"
## [58] "temple" "terrible_old_man" "tomb"
## [61] "tree" "ulthar" "unnamable"
## [64] "vault" "what_moon_brings" "whisperer"
## [67] "white_ship"Now we have a list object, with keys as a (shortened) story title, and a value of a long string that contains the entire story.
str_sub(corpus$cthulhu, 1, 100)## [1] "Of such great powers or beings there may be conceivably a survival...a survival of a hugely remote p"Tokenizing, Stemming and Stop Words
We need to turn this in to a collection of individual words. In NLP parlance, we call this tokenizing. There’s a helpful R library called tokenizers that I’m going to use to do this. We’d also like it if we could count words like ‘go’, ‘going’, and ‘goes’ as the same thing. This is stemming in NLP terminology. Lucky for us, our tokenizer will stem the words as is tokenizes the string, killing two birds with one stone.
The tokenizer also looks for stop words, and omits them. Stop words are really common words in a language that won’t provide any information. Theres an R library that contains lists of stopwords for several languages, called stopwords (naturally). For this analysis, I dont strictly need to remove stop words, but I know they’re not going to be the thing that finds me my next story to read. I’ll remove them all the same.
corpus_toks <- purrr::map(corpus, ~ tokenize_word_stems(.x,
simplify = TRUE,
stopwords = stopwords('en')))
corpus_toks$cthulhu[1:10] ## [1] "great" "power" "be" "may" "conceiv" "surviv" "surviv"
## [8] "huge" "remot" "period"Bags of Words, Frequencies, and TF-IDF
So a basic way of representing a document is the bag of words model. You keep just the word counts, and get rid of anything that would give them context, like order or sentence structure. The important thing we want here is how many times a word occurs in each document. We’ll call this the term frequency (tf).
A ‘short’ story can vary widely in length. And a couple of the documents in our corpus are novels or novellas. We’d like to adjust for that, so we’ll compute word frequency as a percent. While we’re in there we’ll also remove any term with a digit in it. These might represent years or street addresses or whatever, but not anything we’re looking for.
# A function that turns our vector of tokens into a bag of words in a table.
bagify <- function(tokens, docname) {
ntoks <- length(tokens)
tibble(word=tokens, name=docname) %>%
dplyr::filter(!(str_detect(word, '[0-9]'))) %>% # Remove all words with digits
group_by(name, word) %>%
summarise(tf=n()) %>%
arrange(desc(tf)) %>%
ungroup() %>%
mutate(ntoks=ntoks) %>%
mutate(tf_pct=tf/ntoks)
}
# Combine all of these individual tables into a single one.
corpus_bow <- map2(corpus_toks,
names(corpus_toks),
bagify) %>%
reduce(bind_rows) If you think about it though, there’s a problem here: every word has the same importance. A document with a lot of ’the’s in it isn’t necessarily similar to every other document with that many ’the’s, but if we leave this data as-is is, that’s what well be going. We need some way to ascribe less importance to common words, and more importance to rare ones.
So lets think about this problem this way: a word that appears a lot in a handful of documents is more likely to be informative about the document’s topic that a word that appears in all of them. We’ll call the number of documents a term shows up in the document frequency of the term.
ndoc <- length(corpus)
doc_freq <- corpus_bow %>%
group_by(word) %>%
summarise(df=n_distinct(name),
df_pct=n_distinct(name) / ndoc)
# Join the document frequency info back onto the bow table
corpus_bow <- corpus_bow %>% left_join(doc_freq)## Joining, by = "word"Let’s use the document frequency to re-weight the term frequency. That way we’ll placing more importance on terms that are infrequent in the corpus as a whole, but are common in a few documents. We do this by multiplying the term frequency by the inverse of the document frequency. The resulting value is the tf-idf (term frequency-inverse document frequency) statistic for each word in each document in the corpus.
corpus_bow <- corpus_bow %>%
mutate(tfidf=tf_pct * log(ndoc/df))
head(corpus_bow)## # A tibble: 6 x 8
## name word tf ntoks tf_pct df df_pct tfidf
## <chr> <chr> <int> <int> <dbl> <int> <dbl> <dbl>
## 1 alchemist upon 22 1881 0.0117 63 0.940 0.000720
## 2 alchemist age 19 1881 0.0101 48 0.716 0.00337
## 3 alchemist old 16 1881 0.00851 58 0.866 0.00123
## 4 alchemist one 15 1881 0.00797 66 0.985 0.000120
## 5 alchemist curs 14 1881 0.00744 36 0.537 0.00462
## 6 alchemist yet 13 1881 0.00691 63 0.940 0.000425We still haven’t gotten this into a format amenable to math. The we have all the information we need, but its not really easy to use. A natural way to do this would be to make a nice big table, with the words as columns, the works as rows, and the cell values are the word counts. We call this the document-term matrix.
dtm <- corpus_bow %>%
filter(df > 2) %>%
dplyr::select(name, word, tfidf) %>%
rename(rowname=name) %>%
spread(word, tfidf, fill=0) %>%
column_to_rownames
# Peek at the corner
dtm[1:5,1:5]## a.d a.m abandon abat abdul
## alchemist 0 0 0.0004831769 0 0
## arthur_jermyn 0 0 0.0000000000 0 0
## azathoth 0 0 0.0000000000 0 0
## beast 0 0 0.0007431363 0 0
## beyond_wall_of_sleep 0 0 0.0000000000 0 0Finally, I have some metadata about the stories we’ll use later to identify the dream cycle stories.
metadata <- read_csv('metadata.csv') %>%
mutate(dreamlands=ifelse(dreamlands==1, "Yes", "No"))
dreamlands_works <- metadata %>% filter(dreamlands == "Yes") %>% pull(name)Word Importance
We can use the tidf scores to find what words are important for each work. Let’s look at the distribution of tfidf in our corpus. Because we’re weighting by inverse document frequency, we’ll want to filter out all the words that have low document frequency, just to squelch some of that noise.
corpus_bow %>%
filter(df > 3) %>%
summarise(unique_words=n_distinct(word),
tfidf_mean=mean(tfidf),
tfidf_sd=sd(tfidf),
tfidf_median=median(tfidf),
tfidf_max=max(tfidf))## # A tibble: 1 x 5
## unique_words tfidf_mean tfidf_sd tfidf_median tfidf_max
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 5425 0.000713 0.00119 0.000410 0.0604Lets look at the most important words in the dataset:
corpus_bow %>%
filter(df > 3) %>%
arrange(desc(tfidf)) %>%
dplyr::select(name, word, tf, df, tfidf) %>%
top_n(10)## Selecting by tfidf## # A tibble: 10 x 5
## name word tf df tfidf
## <chr> <chr> <int> <int> <dbl>
## 1 ulthar cat 26 14 0.0604
## 2 randolph_carter warren 23 5 0.0522
## 3 other_gods hatheg 18 4 0.0515
## 4 gates_of_silver_key carter 150 6 0.0482
## 5 nyarlathotep nyarlathotep 11 7 0.0417
## 6 pickman pickman 42 5 0.0409
## 7 ulthar ulthar 11 6 0.0394
## 8 memory ape 3 8 0.0364
## 9 doorstep edward 66 4 0.0358
## 10 kadath carter 317 6 0.0343We see some obvious things in here: ‘Nyarlathotep’ is important to Nyarathlotep, ‘Ulthar’ is important to The Cats of Ulthar. But we also see some potentially interesting things. The word ‘Carter’ is important to both The Dream Quest of Unknown Kadath and Through the Gates of the Silver Key. Thats because both of thse stories share a protagonist, Randolph Carter 2. ‘Thou’ is important to Poetry of Gods because it’s written in that old-timey formal style.
corpus_bow %>%
filter(df > 3) %>%
filter(name=='cthulhu') %>%
arrange(desc(tfidf)) %>%
dplyr::select(name, word, tf, df, tfidf) %>%
top_n(10) ## Selecting by tfidf## # A tibble: 10 x 5
## name word tf df tfidf
## <chr> <chr> <int> <int> <dbl>
## 1 cthulhu professor 32 10 0.00962
## 2 cthulhu uncl 27 8 0.00907
## 3 cthulhu cult 38 15 0.00899
## 4 cthulhu cthulhu 23 7 0.00822
## 5 cthulhu sculptor 11 5 0.00451
## 6 cthulhu bas 12 7 0.00429
## 7 cthulhu r'lyeh 10 5 0.00410
## 8 cthulhu alert 12 8 0.00403
## 9 cthulhu inspector 9 5 0.00369
## 10 cthulhu april 12 10 0.00361Some things pop up here. The most important term is ‘Uncl’, but thats a strange word. ‘Uncle’ is actually an inadvertent stemming of ‘uncle’. The Call of Cthulhu is framed as a story of a man going through items his dead uncle left him, so ‘uncl’ coming up at the top makes a lot of sense. ‘Cthulhu’ (and “R’lyeh”) come up of course. And without giving anything away, I’ll say that if you’ve read the story, you know why the other terms are important. Tfidf is working pretty well here: we can get a good idea of the themes in a story just by ranking the terms.
What about The Shadow Over Innsmouth? It has: innsmouth, o, em, marsh, reef, fish, street, fer, arkham, folk I can’t actually say anything about this story without giving anything away. So thats a good sign. It’s actually kind of difficult to get a good, spoiler-free set of words. Mountains of Madness has: lake, camp, sculptur, plane, us, ice, specimen, mountain, rampart, wireless. For a story about an explorer’s expedition to the south pole, that’s a good set of words.
Document similarity
A common way to define the how closely two documents are related is cosine similarity. In short: any vector (in our case the rows in the document-term matrix) can be thought of as ‘pointing’ in a certain direction. Cosine similarity is a measure of the angle between two vectors. Mathematically, the cosine similarity of two vectors is \[ \cos \theta = \frac{\mathbf{a}^T \mathbf{b}}{\| \mathbf{a} \| \| \mathbf{b} \|}\]
If two vectors point in the exact same direction, the similarity is 1. If they point in opposite directions, cosine similarity is -13. If they are perpendicular, cosine similarity is 0. Magnitude of the vector isn’t important, what is important is that they point the same way.
R actually doesn’t have a built in function to perform cosine similarity. There are plenty of packages that do, though. I’ll use the implementation in lsa, since I’ll be using that package later. It’s a pretty straight-forward equation but I’ll spare you the matrix algebra.
# lsa's functions are all set up for term-document matrices and not
# and not vice-versa, so we transpose
lovecraft.sim <- lsa::cosine(t(dtm))How well are we modelling similarity between the our selected stories?
cl <- c('dunwich', 'cthulhu', 'innsmouth', 'mountains_of_madness')
lovecraft.sim[cl,cl]## dunwich cthulhu innsmouth mountains_of_madness
## dunwich 1.0000000 0.1881106 0.3502657 0.2340548
## cthulhu 0.1881106 1.0000000 0.1678855 0.2297371
## innsmouth 0.3502657 0.1678855 1.0000000 0.1898816
## mountains_of_madness 0.2340548 0.2297371 0.1898816 1.0000000Looks reasonable. So how close are Dagon and The Call of Cthluhu?
lovecraft.sim['dagon', 'cthulhu']## [1] 0.1708165Not super close. But its hard for two documents to point closely in the same direction. They’d have to use the same vocabulary in the same relative amounts. That’s a tall order. Let’s look at what other works Dagon was similar to.
lovecraft.sim['dagon',] %>%
sort(decreasing=T) %>%
as.data.frame() %>%
set_names("CosineSim") %>%
rownames_to_column("name") %>% top_n(10)## Selecting by CosineSim## name CosineSim
## 1 dagon 1.0000000
## 2 temple 0.2318079
## 3 mountains_of_madness 0.1812425
## 4 cthulhu 0.1708165
## 5 martins_beach 0.1704065
## 6 shadow_out_of_time 0.1602591
## 7 nameless 0.1437375
## 8 innsmouth 0.1343936
## 9 whisperer 0.1295694
## 10 lurking_fear 0.1278216Not too bad. The Call of Cthulhu shows up as the 3th closest to Dagon. So we’re in the ballpark.
Looking at our whole distribution of cosine-similarities we can see that most are < 0.1. So having Cthulhu and Dagon at 0.1708165 isn’t too shabby.
sim_distr <- lovecraft.sim %>%
as.data.frame() %>%
rownames_to_column("name1") %>%
gather("name1", "CosSim") %>%
filter(CosSim < 1)
sim_distr %>%
filter(CosSim < 0.99) %>%
summarise(mean=mean(CosSim),
sd=sd(CosSim),
median=median(CosSim),
min=min(CosSim),
max=max(CosSim))## mean sd median min max
## 1 0.08937463 0.05465962 0.07855943 0.009112144 0.7039202ggplot(sim_distr, aes(x=CosSim)) + geom_density()
Lets look at The Whisperer In Darkness and The Colour Out of Space:
lovecraft.sim['colour_out_of_space', 'whisperer']## [1] 0.2900305Pretty good! They’re both about aliens so I’d say that some of that vocabulary might be driving the similarity.
What’s driving the similarity?
We can figure out pretty easily which terms are driving the similarity. When we look back at our definition of cosine similarity, the important term for us is \(\mathbf{a}^{T}\mathbf{b}\). We can ignore the denominator right now (\(\|\mathbf{a}\| \|\mathbf{b} \|\) is a scalar, not a vector, so it’s the same for every pair of words in the vectors). The numerator is computed as \(\mathbf{a}^{T}\mathbf{b} = \sum \mathbf{a}_i\mathbf{b}_{i}\). Since we know that all our elements are positive, what’s important for the cosine similarity are the vectors where \(\mathbf{a}_i\mathbf{b}_i\) is large. 4
similarity_drivers <- function(work1, work2, topn=5) {
l2.norm <- function(v) sqrt(sum(v^2))
# Scaling wont make a difference in the ranking
# but it will keep the numbers from getting very small.
#
# Since we unit-scale when we do cosine similarity,
# lets unit-scale here too.
v1 <- dtm[work1, ] / l2.norm(dtm[work1, ])
v2 <- dtm[work2, ] / l2.norm(dtm[work2, ])
(v1 * v2) %>%
t %>%
as.data.frame() %>%
rownames_to_column() %>%
set_names('word', 'tfidf_prod') %>%
arrange(desc(tfidf_prod)) %>%
top_n(topn)
}So what makes Whisperer In Darkness and The Colour Out of Space in this model? The most important terms are: road, arkham, get, wood, farm, everyth, dog, rustic, farmer, hill. We can see some of the setting elements here, with road and farm coming up, and some of the Lovecraftian elements (‘thing’ is a very on-brand word to come up as important).
The closest story to Call of Cthulhu in this model is The Shunned House. The main driver here is ‘uncl’. We already talked about uncles and Call of Cthulhu, and a similar thing is happening with Shunned House, which is a story about the protagonist and his uncle investigating a strange house.
The whole 67x67 similarity matrix is kind of a lot to put on a heatmap and have the labels remain legible, but there’s still stuff we can do. A lot of things we might want to do work with distances instead of similarities, but we can convert. 5 Since we know our similarities are bounded between 0 and 1, we can just take the complement, and use that.
lovecraft.dist <- as.dist(1-lovecraft.sim)Visualization
Finally let’s take a look at the data. We’ll use multidimensional scaling (MDS) to visualize. MDS tries to place datapoints in a new, lower-dimensional space while perserving distances.
hp.mds <- cmdscale(lovecraft.dist)
hp.mds.coords <- hp.mds %>%
as.data.frame() %>%
set_names(c("Dim1", "Dim2")) %>%
rownames_to_column("name") %>%
left_join(metadata) ## Joining, by = "name"ggplot(hp.mds.coords, aes(x=Dim1, y=Dim2, label=name)) +
geom_point(aes(color=dreamlands)) +
geom_text_repel(size=2) +
theme_classic() +
xlab("MDS1") +
ylab("MDS2")
The most obvious thing in this plot is that Kadath and the Silver Key stories are out on their own. When we look at our similarity matrix we can see that these have really high similarity. Through the Gates of the Silver Key is not a dream cycle work, it was inspired by Silver Key, so it’s not surprising to see them close togther.
cl <- c('kadath', 'silver_key', 'gates_of_silver_key', 'randolph_carter')
lovecraft.sim[cl,cl]## kadath silver_key gates_of_silver_key
## kadath 1.0000000 0.5551133 0.7039202
## silver_key 0.5551133 1.0000000 0.6879951
## gates_of_silver_key 0.7039202 0.6879951 1.0000000
## randolph_carter 0.1957166 0.1750636 0.2391834
## randolph_carter
## kadath 0.1957166
## silver_key 0.1750636
## gates_of_silver_key 0.2391834
## randolph_carter 1.0000000When we look at the similarity matrix, we see that these three stories are extremely similar works, at least by their TF-IDF weighted vocabulary.
The rest of the works sit on a single axis in this space6. With the color coding we can see that the a lot of the dream cycle stories sit at one end of the axis, and stories like The Dunwich Horror and The Whisperer in Darkness sit at the other end. It’s not that clean of a dilineation though, Dreams in the Witch House and The Outsider are dream cycle stories that are right in the middle of the axis, with non-dream cycle stories around it. Poetry of the Gods isn’t a dream cycle work by Wikipedia’s listing, but it looks like it may as well be.
The Statement of Randolph Carter comes off well off the axis as well, without being part of the dream cycle. Statement isn’t a dream cycle story, but ‘Randolph Carter’ is a character in Kadath and the Silver Key stories. I suspect that the TF-IDF weighting of the name or common descriptions used along with the character7 are responsible for Statement’s location in MDS-space. Statement is a pre-dream cycle story, but I’ll have to give it another read to see if its working with the same themes. The Unnamable comes off for the exact same reason: Randolph Carter is there. Carter is mentioned in passing in The Case of Charles Dexter Ward but the single mention wasn’t enough to move that datapoint8.
Let’s test my hypothesis about Carter being an important part of the similarity:
similarity_drivers('kadath', 'silver_key')## Selecting by tfidf_prod## word tfidf_prod
## 1 carter 0.452119618
## 2 randolph 0.019493526
## 3 ulthar 0.001584717
## 4 hill 0.001313051
## 5 wood 0.001308327Seems convincing.
Latent Semantic Analysis
So there are two big things we haven’t accounted for. First is the curse of dimensionality. When we’re looking at a lot of dimensions, everything becomes very ‘far’ from everything else. The 6539 dimensions we have for our document-term matrix is a lot of dimensions. As a result we may be understating our similarities for various documents.
Secondly, we haven’t considered correlations between terms. A story like Dagon has a lot of important words that are related to each other: boat, fish, monolith, ocean, gibbous, whale. Finding ‘boat’, ‘fish’, and ‘whale’ together shouldn’t be surprising, it’s a story that takes place at sea. But we don’t want to count them as independent evidence of similarity. Together they represent the ‘sea’-ness of the story. They’re all related by that concept. So we may also be overstating our similarities when they share important terms.
We want a way to both reduce the dimensionality of the data and account for these term correlations. We can do both by using latent semantic analysis on our data. LSA performs a singular value decomposition on our matrix to come up with a new, lower-dimensional space that still describes the space well. If you’ve used principal components analysis before, this is very closely related.
I’ll break from my do-it-by-hand approach here to save you from reading me doing matrix algebra. Instead we’ll use the implementation from the lsa package. This is a pretty small sample size for LSA, but we’ll try it out anyway. In a normal analysis, we’d tune the number of dimensions, but he’re we’ll roll with lsa’s defaults.9
# LSA is mostly described and implemented for matrices with
# terms as rows and columns as documents. That's just a quick
# transpose away from the data
tdm.tfidf <- t(dtm)
lovecraft.lsa <- lsa(tdm.tfidf)
dtm.lsa_space <- lovecraft.lsa$dk
# Calculate our similarities
lovecraft.sim.lsa <- lsa::cosine(t(dtm.lsa_space))
lovecraft.sim.lsa <- pmin(pmax(lovecraft.sim.lsa, -1.0), 1.0)
lovecraft.dist.lsa <- as.dist(acos(lovecraft.sim.lsa) / pi)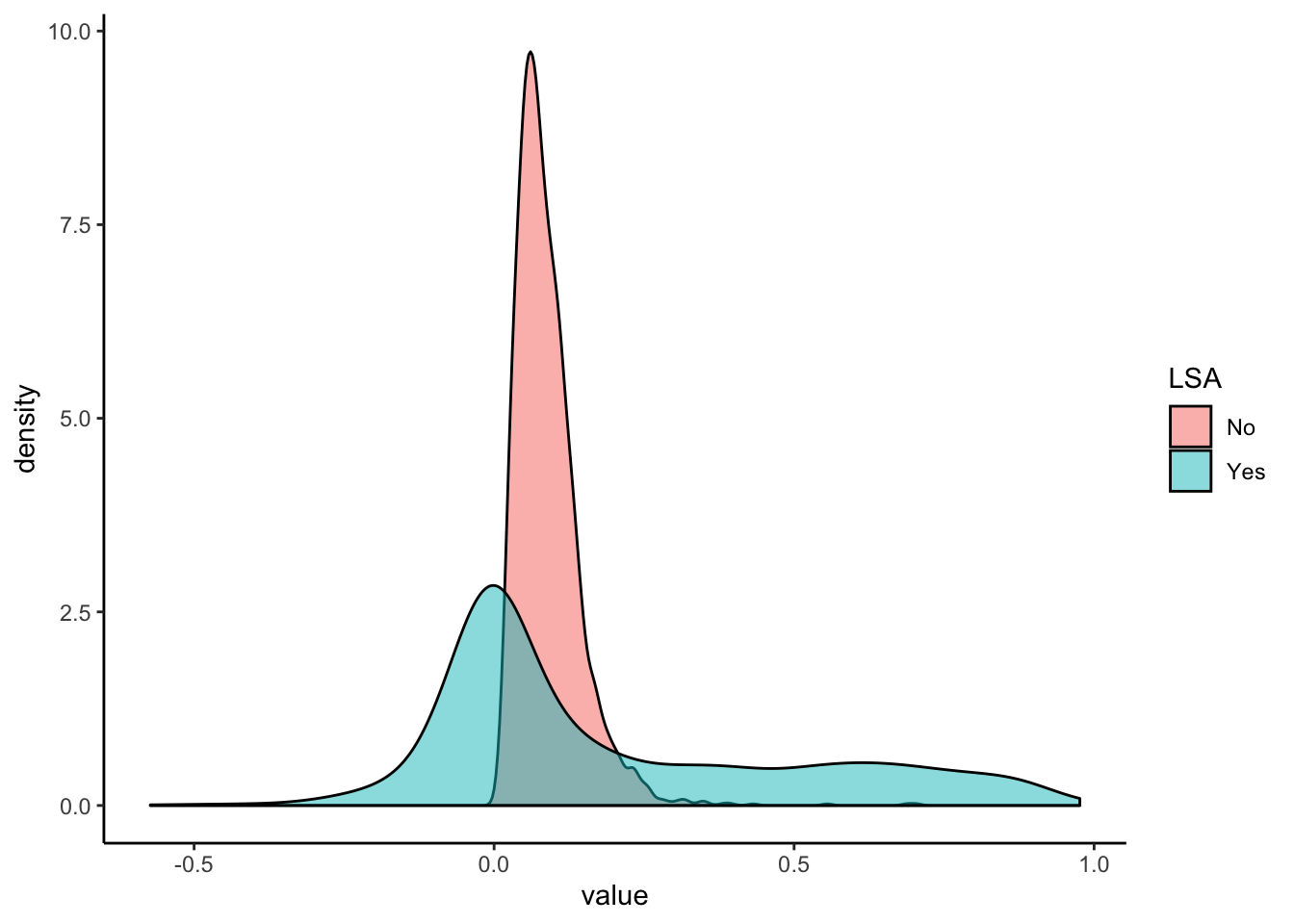
So we have some big differences here. First, we have negative cosine similarities now. The transformation into latent space has result that our new document-term matrix isn’t all positive. The other really noticable thing is that we have a lot more similar documents. Instead of all clumping near 0.1, we have a nice spread across the range. It appears from the density plot that we don’t have a lot of similarities in the middle range, they’re mostly high or low.
You can’t see it in a plot but the other thing we’ve lost is some of our interpretability. Instead of looking at the tf-idf of words, we’re looking at scores for combinations of words. Trying to figure that out is opening a can of worms. And now that we have negative values in our reduced document-term matrix, we couldn’t use our dot product similarity trick from earlier without modification even if we wanted to.
Visualization again.
lovecraft.lsa.mds <- cmdscale(lovecraft.dist.lsa)
lovecraft.lsa.coords <- lovecraft.lsa.mds %>%
as.data.frame() %>%
set_names(c("MDS1", "MDS2")) %>%
rownames_to_column("name") %>%
left_join(metadata) ## Joining, by = "name"ggplot(lovecraft.lsa.coords, aes(x=MDS1, y=MDS2, label=name)) +
geom_point(aes(color=dreamlands)) +
geom_text_repel(size=2.5) +
theme_classic() +
theme(legend.position = 'bottom',
legend.direction = 'horizontal')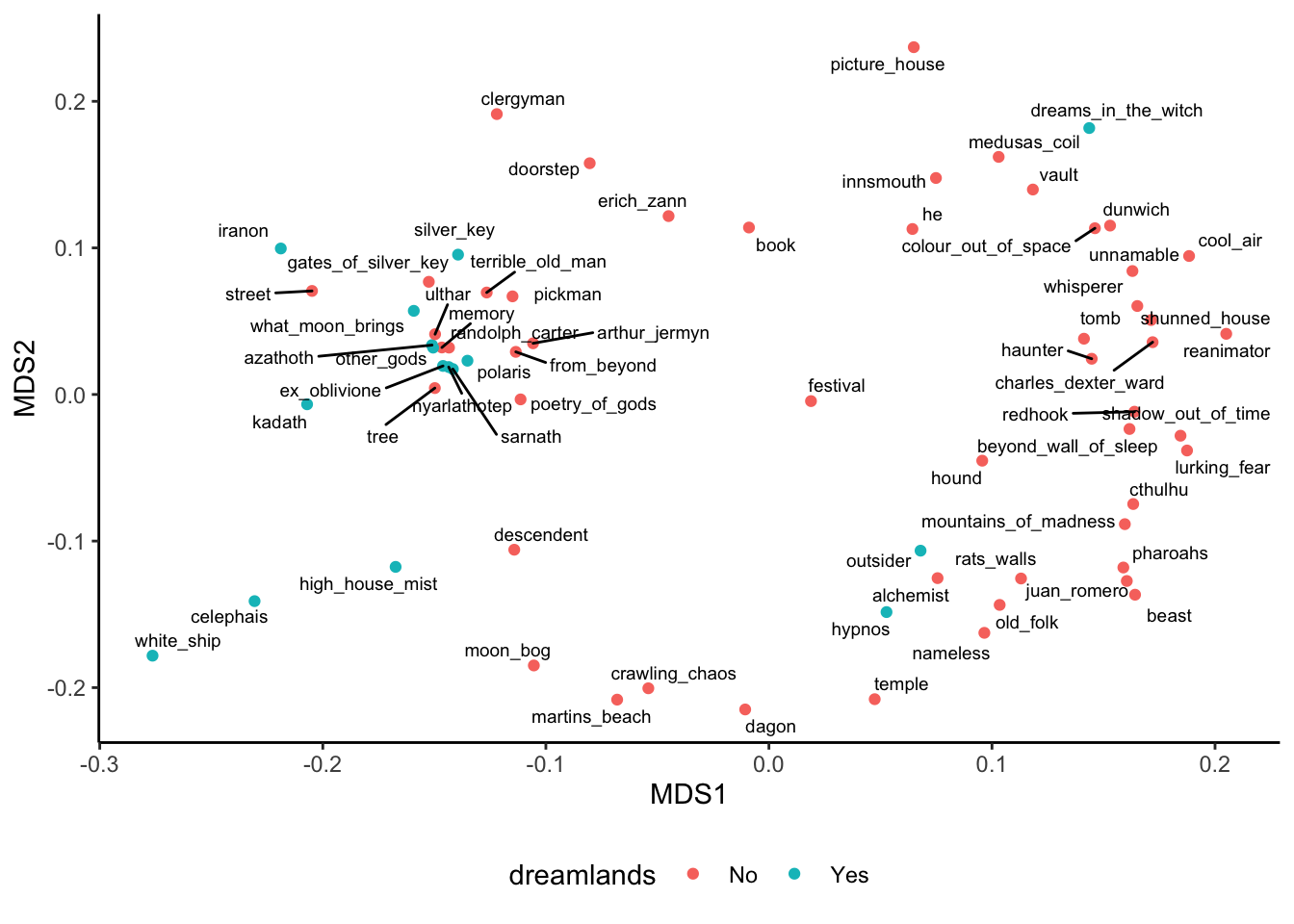
Theres a lot of structure here. We see one very tightly focused group in the middle which is mostly dreamlands stories. Outside of this group, curling around, we see the rest of the stories. Their placement seems to indicate a pretty good embedding given my prior understandings of the book: Mountains of Madness near Call of Cthulhu, Dunwich Horror near Innsmouth, etc. We didn’t get Dagon that close to Cthulhu here (their cosine similarity was 0.5489908).
Conclusions
From my perspective, we’ve got a pretty good model of corpus. The tf-idf weighted important terms for the stories I read feel pretty representative. There are some similarities where we expected, so I’m feeling pretty good about finding similar stories to the ones I like. Our classic Cthulhu Mythos stories showed reasonable cosine similarity, and we could identify the Dream Cycle works in the lower-dimensional space.
For a pretty simple way to represent something as complicated as fiction, tf-idf served us very well in identifying comomon phrasings. We found the ‘uncle stories’ Call of Cthulhu and Shunned House. We couldn’t model the similarity between Dagon and The Call of Cthulhu super convincingly (but it is there), but we did get good similarity between The Colour Out of Space and The Whisperer in Darkness. The Silver Gate stories as well as The Dream Quest Of Unknown Kadath were closely related in this model. I didn’t think of it ahead of time, but the character of Randolph Carter is very visible in both the clustering dendrogram and in MDS space.
Looking past individual words into latent meanings, we found a lot more structure in the corpus. We found that “Dreamlands” cluster we expected, and the rest of the embeddings made sense in their contexts. I haven’t read The Hound, but since its sitting next to Cthulhu (one of my favorites) in the MDS plot, it seems like a good choice for my next read.
There’s still a lot of work to be done on this corpus. Formal topic modelling would be a good next step.
Appendix: Things that didnt work
Statistical analysis is often an iterative process, where you try something and it doesnt work, so you try something else. Most tutorials are written as if everything went great on the first try. I don’t want to be like that.
Not filtering out terms with low document frequency when looking for characteristic terms for a document. I mostly ended up with names.
- Classical MDS worked well for the tfidf data, but non-metric MDS (as implemented in
MASS::isoMDS). This gave me embeddings that didnt really make sense given the similarities (e.g. The Silver Key was far from Through the Gates of the Silver Key). Hierachical clustering of the tfidf (i.e. non-LSA) data wasn’t convincing because everything was far from everything else.
I can’t stress this enough. I just made you go to a footnote so that I could tell you again↩
‘Carter’ isnt actually an important term for The Statement of Randolph Carter. That story is written in first-person, and Carter doesn’t spend a lot of time saying his own name.↩
If that sounds suspiciously similar to Pearson’s r to you, thats because it is. The correlation coefficient is actual a special case of cosine similarity: they are the same when the variables are centered. With the data we have it doesn’t make much sense to center it, and cosine will work just fine.↩
Precisely, we can define the Hadamard product of two matrices (and a vector is just a kind of matrix) as \((\mathbf{A} \odot \mathbf{B})_{ij} = \mathbf{A}_{ij} \mathbf{B}_{ij}\). We compute this for a pair of rows in the document-term matrix. The values are then the scalar product of each term’s tfidf score.↩
Technically we’re not making distances, we’re making dissimilarities. Cosine similarity doesn’t satisify the triangle inequality, which is required to be a proper distance metric. Luckily, what we’ll be doing works just fine with dissimilarities.↩
This axis was a common feature of several lower-dimensional embedding strategies I tried on the non-LSA data. For example, t-SNE and UMAP both had it, but didn’t get the Silver Key/Kadath group off the axis. MDS on the document-term matrix with those stories removed looks similar, with The Other Gods and Cats of Ulthar off in the distance. The difference in results wasn’t worth making this already long post longer.↩
I looked through the text of The Statement of Randolph Carter, and ‘Randolph’ only appears once↩
Carter apparently appears one more time in 1933’s Out of the Aeons, a Lovecraft collaboration with Hazel Heald. I don’t bring this up because 1) it wasn’t in my corpus, and 2) according to wikipedia, Carter appears (again in passing) under an assumed name he uses in Through the Gates of The Silver Key↩
I did do a bit of playing around with the dimensions and the defaults actually did pretty well.↩